第6期:Hadoop体系结构
2019-08-19Hadoop被公认是一套行业大数据标准开源软件,主流厂商都围绕Hadoop开发工具、开源软件、商业化工具和技术服务。由于现代社会的信息量增长速度极快,这些信息里又积累着大量数据,其中包括个人数据和工业数据。Hadoop帮助我们对这些数据进行分析和处理,以获取更多有价值的信息。
01—大数据应用
大数据本身探寻的是一种趋势,而非精准性,大数据时代需要学会接受数据的不完美。

大数据让更多的创业者更方便地开发产品,推动行业的创新、变革、发展,同时也改变了人们的生产生活方式。

02—Hadoop简介
Hadoop的开发厂商的发行版除了社区的Apache Hadoop外,EMC、IBM、ORACLE等公司都提供了自己的商业版本 。

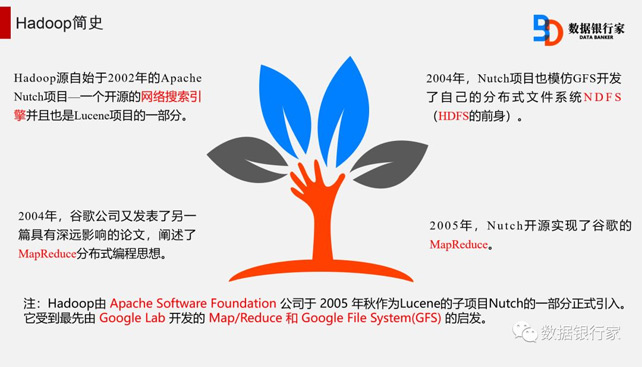
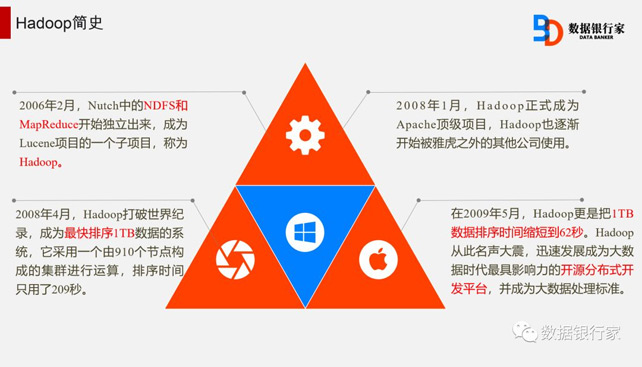
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台。以HDFS和MapReduce为核心,为用户提供了系统底层的分布式基础架构。
Hadoop是一个能够对大量数据进行分布式处理的软件框架,并且是以一种可靠、高效、可伸缩的方式处理,它具有诸多特性。

随着企业产生数据 量的迅速增长,存储和处理大规模数据已成为企业的迫切需求。Hadoop作为开源的云计算平台,已引起了学术界和企业的普遍兴趣。

03—Hadoop生态系统
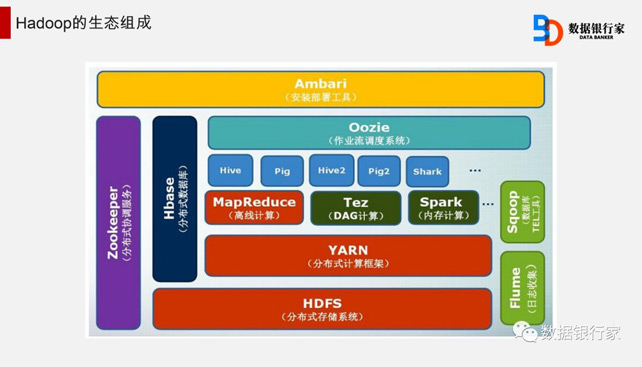
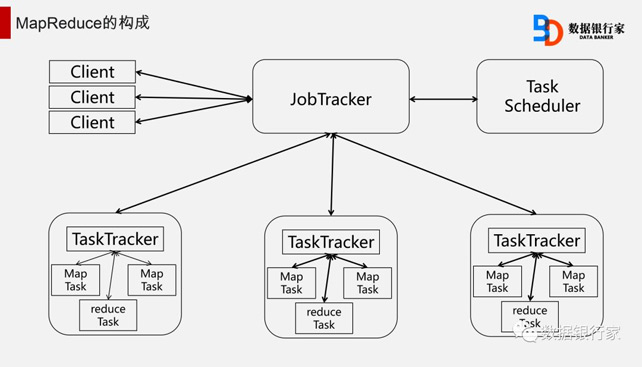
Hadoop的体系结构主要是通过HDFS来实现对分布式存储的底层支持,并通过MapReduce实现对分布式并行任务的处理。
MapReduce是一个简单易用的软件框架,它可以将任务分发到由上千台商用机器组成的集群上,并以一种高容错的方式并行处理大量数据集,实现Hadoop并行任务处理功能。
将大数据集分解为成百上千个小数据集,每个数据集分别由集群中的一个节点进行处理并生成中间结果,然后大量的节点将这些中间结果合并,形成最终结果。
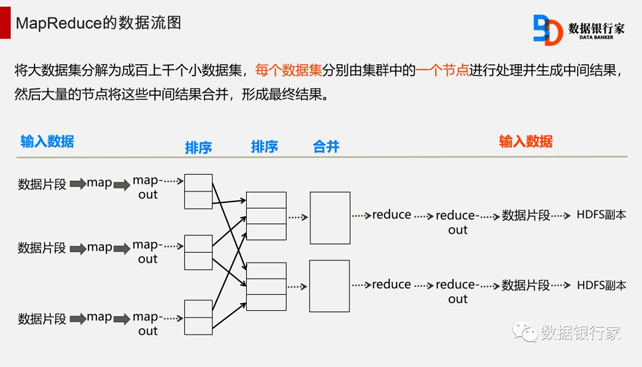
MapReduce是Google公司的核心计算模型,这是一个简单却又威力巨大的模型,它将运行于大规模集群上的复杂并行计算抽象为两个函数:Map和Reduce。

HDFS是基于流数据模式访问和处理超大文件的需求开发的,它可以运行于廉价的商用服务器上,HDFS设计时的目标包括以下几个方面。

Hadoop文件系统采用主从架构对文件系统进行管理,一个HDFS集群由唯一名称节点(NameNode)和数个数据节点(DataNodes)组成

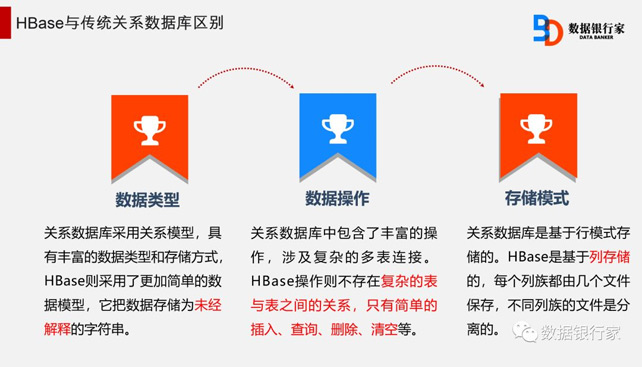
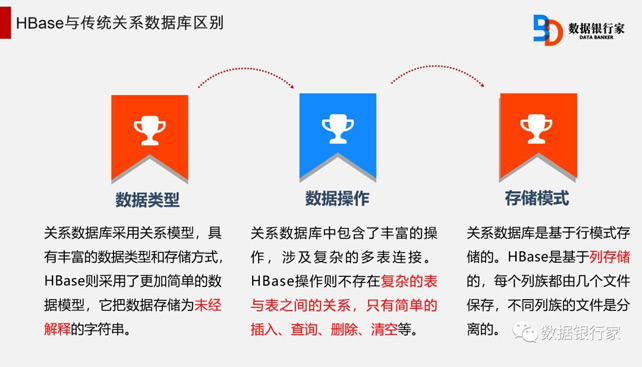
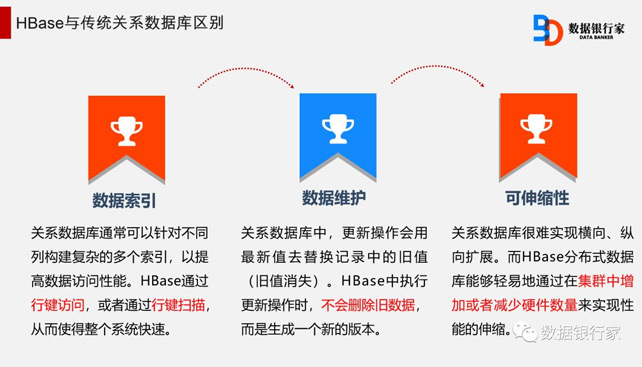
HBase—Hadoop Database,是一个高可靠、高性能、面向列、可扩展的分布式存储系统,利用HBase技术可在廉价PC服务器上搭建起大规模结构化存储集群。

HBase不同于普通的关系数据库,它适用于非结构化数据存储的数据库,并且HBase采用了基于列而不是基于行的模式。
Hive是Facebook开发的,构建于Hadoop集群之上的数据仓库应用。2008年Facebook将Hive项目贡献给Apache,成为开源项目。

Hive提供的是一种结构化数据的机制,它支持类似于传统RDBMS中的SQL语言以帮助那些熟悉SQL的用户查询Hadoop中的数据。
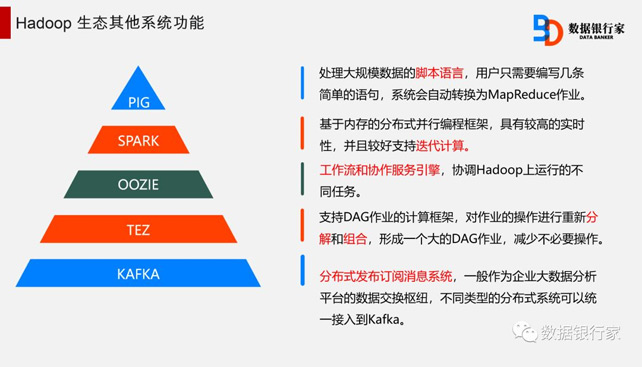
Hadoop已经发展成为一个包含多个子项目的集合,被用于分布式计算,Avro、Hive、HBase 等子项目提供了互补性服务或在核心层之上提供更高层的服务。